


This is a research report on Generative AI that I recently wrote for my investment team, “TUIT” — I reference it in the paper. Honestly, I’m not exactly sure what the big takeaway is, but the report gets pretty technical. If it gets confusing, the main idea is: AI is cool. If you’re new to the blog, these industry deep dives aren’t super common. My goal is to write more casually.
The internet’s latest sensation, reaching over one million users in a week, is ChatGPT – an artificial intelligence chatbot launched by OpenAI in November 2022. To learn more about what it actually was, I did what millions of individuals have done over the last couple of months and asked it a question: How does ChatGPT work?
Here’s its response:
“ChatGPT is a variant of the GPT (Generative Pre-training Transformer) language model that has been specifically designed for use in chatbot applications. It is trained to predict the next word in a conversation based on the words that have preceded it, functioning in a manner analogous to GPT-3.”
Before diving more into the previous response and how ChatGPT actually works, here’s it explaining itself to a five-year-old:
“Okay, imagine you have a computer program that is really good at pretending to be a person and having a conversation with you. It's called ChatGPT because it uses something called a "generative" model to come up with responses to what you say. This means that it tries to generate new text that sounds like it could have come from a real person. It's kind of like a robot that you can talk to and have a conversation with. It's not a real person, but it can pretend to be one!”
Large language models (LLMs), like ChatGPT, are a type of natural language processing (NLP) – the umbrella branch of computer science and artificial intelligence that focuses on giving computers the ability to understand text and spoken language. Within NLP, distinctions among various models can be loosely separated into two main categories: statistical models and neural language models.
Statistical Models
Statistical models are developed probabilistic models that help predict following text in a sequence based on those that preceded. Typically operating at the level of words – although larger models can work at the level of sentences or paragraphs – these models learn based on examples of text. At its core, a statistical model is based on a Markovian Assumption, or the assumption that the probability of a certain event depends solely on the past k events. This is what that looks like in relation to words using the most basic N-gram model, a 1-gram or unigram:
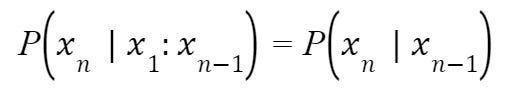
The example above is the simplest approach to statistical modeling, but there are other types of the N-Gram model such as bigrams, trigrams, etc. As a result, there are a variety of other models based on the below equation:
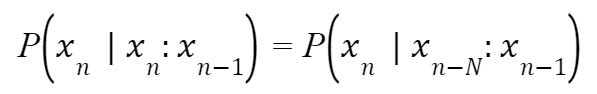
I’ll also give a written interpretation of various n-grams. Consider this phrase: TUIT is the best investment team at UT. A unigram would create a one-word sequence: TUIT, is, the, best, investment, team, at, UT. A bigram, however, would create two-word sequences: TUIT is, the best, investment team, at UT.
We further build upon this by combining this model with feature functions to create an exponential model. By defining the features and parameters of the desired result, the model would yield a more accurate model given the principle of entropy – probability distribution with more entropy is more accurate because of fewer statistical assumptions. Statistical models have long provided the base for common AI projects including speech recognition, spelling correction, image captioning, text summarization, and more. However, in pursuit of more refined, complex NLP tasks neural language models have quickly gained popularity.
Neural Language Models
Neural language models provide the basis for familiar projects such as DALL-E and ChatGPT by utilizing a series of neural networks to solve a variety of NLP tasks. At a high level, the utilization of neural networks mimics the functionality of human brains, utilizing a network of connected nodes with various weights that allow the inputs of some to become the output of others. Diving further, there are three main neural networks utilized within neural language models:
1. Artificial Neural Networks (ANNs)
A single node or neuron within the network can be visualized as a logistic regression. An ANN has a series of multiple nodes in three layers – input, hidden, and output. The input layer accepts the inputs, the hidden layer processes the inputs, and the output layer produces the output. Pretty self-explanatory. Here’s what that looks like:
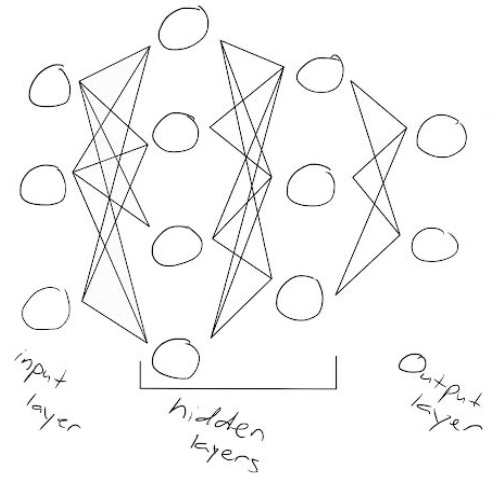
ANNs are also known as Feed-Forward Neural Networks because inputs are only processed in one direction, as seen above. Moving in that direction, the processes of the network occur due to various weights assigned. In the hidden layer, the weighted sum of the various inputs is taken and sent to the output layer where the activation function – the key to ANNs – decides if the individual neuron deserves to be activated for the prediction.
2. Recurrent Neural Networks (RNNs)
RNNs are similar to ANNs, but have a looping constraint within the hidden layer. From an architectural perspective here’s an idea of what that difference looks like:
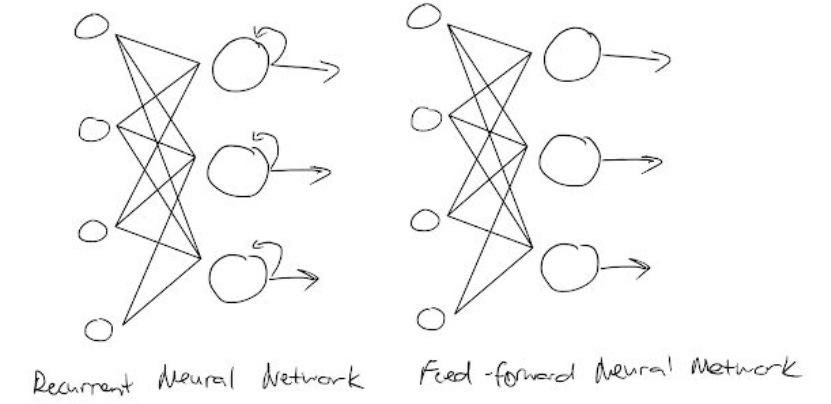
The looping constraint ensures that sequential information is captured in the input data, limiting the number of parameters that the model has to learn. This streamlines the training process severely. Given an n number of steps, a regular forward feed would have to learn n parameters. With large parameter datasets, it’s easy to imagine how the processing power of the model would slow down. RNN’s loops allow models to take advantage of various patterns within sentence structure in sequence learning. Take the phrases, Yesterday I built a DCF and I built a DCF yesterday. These two sentences mean the same thing, but the important part – I built a DCF – happens at different parts. A regular model would need to train both iterations, but RNNs can train fewer parameters, decreasing the computational cost – this is called parameter sharing.
3. Convolution Neural Networks (CNNs)
Convolution Neural Networks are extremely popular right now, primarily in projects involving image and video processing. CNNs take an image as input, assign importance to various parameters within the image that help define it, and differentiate the many aspects within the image. A simple ANN might be able to process extremely basic binary images but would quickly falter when tasked with predictions for a more complex image with a large number of pixel dependencies. Through an application of filters, a CNNs architecture allows it to successfully capture spatial (picture) and temporal (video) dependencies. To do so, the CNN input takes something called a kernel – the first part of a convolutional layer. This kernel is a filter defined as K, a certain matrix. For example, if we had a 5x5x1 image layer, we could define K as 3x3x1 – a smaller sub-segment of the overall image. From there, the kernel shifts throughout the image in the below format performing an element-wise multiplication operation (Hadamard Product):
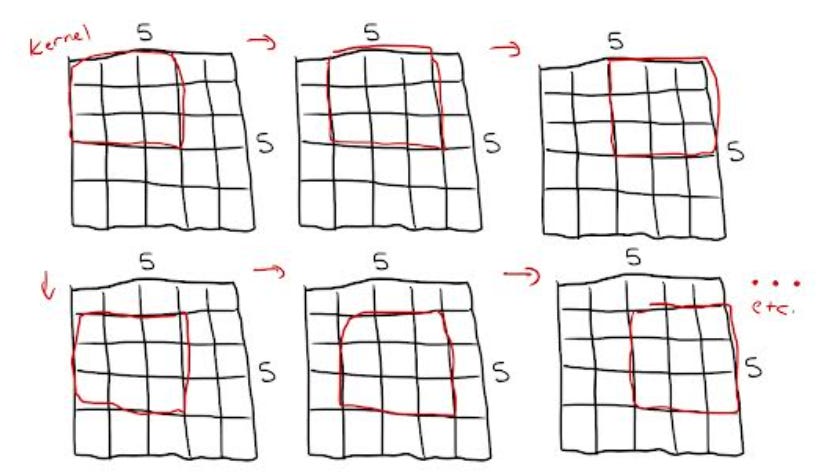
When handling an image with multiple layers, the kernel would have the same depth as the input image. For example, a 5x5 RGB image would be defined with a 5x5x3 matrix. Its subsequent kernel could be then defined by a 3x3x3 matrix. Performing the matrix multiplication and allowing the kernel to extract various aspects of the image within each kernel iteration, starting with lower-level features such as color and edges and moving on to higher-level features later on. The overlap between kernel iterations allows for strong parameter sharing, boosting the model’s overall efficiency.
There are two possible outcomes to the previous operation: decreased dimensionality in the convolved feature when compared to the input and increased or equal dimensionality. As a result, the next step varies between applying valid padding or the same padding respectively to the two outcomes. Padding refers to the pixels added to an image when being processed by the kernel. Given an image with a pixel value of zero, increasing the padding from zero to one would add a one pixel border to the image. By doing so, the kernel has more space to cover the image, allowing the accuracy of the processing to be stronger. This is an example of padding:
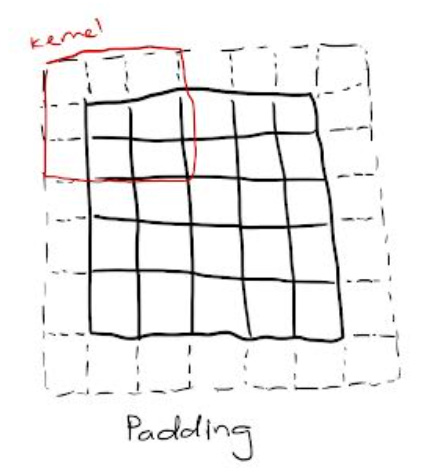
Similar to the convolutional layer, CNNs also have a pooling layer that is responsible for reducing the spatial size of the convolved feature, decreasing the computational power required to process the data. There are two main types of pooling: max and average pooling. Max pooling returns the maximum value from the portion of the image covered by the kernel, while average pooling returns an average of all values over the same portion. Typically, max pooling is the better alternative because of its noise suppression of all the other values. Combining the convolutional layer and the pooling layer together forms the nᵗʰ layer of a CNN. Further convolution and pooling layers can be put together to capture even more lower-level features,
depending on the complexity of images and computational power.
The last step involves flattening the final output and feeding it to the neural network for classification purposes. This converts all the resultant two-dimensional arrays from pooled feature maps into a single long continuous linear vector which is fed as input to the fully connected layer to classify the image. With all the steps together, this is what it looks like:
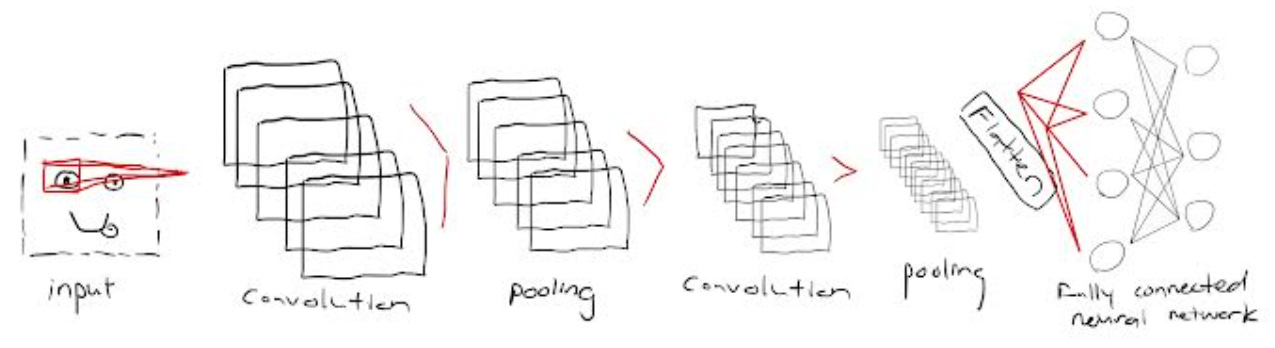
Generative AI
Now, with a good idea of how the brains of various neural networks work, I want to introduce generative AI – the artificial creation of new content through using existing text, audio, or video files. As one of the primary ways engineers have been utilizing neural networks, there are three main techniques used to create generative AI:
1. Generative Adversarial Networks (GANs)
GANs are algorithmic architectures that pit two neural networks against each other – hence adversarial – to create new instances of data. Typically working with visual image data, GANs largely use CNNs as both networks within their model architecture. Here’s a visual:
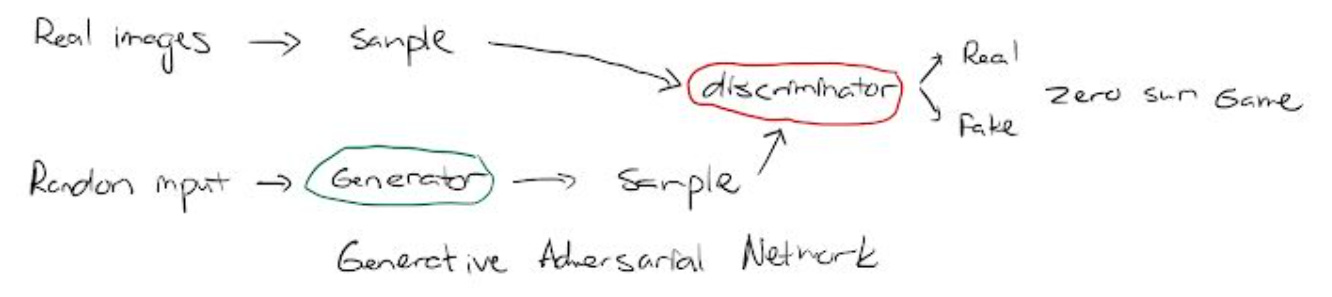
As mentioned above, and seen in the diagram, GANs utilize two models: a generator and a discriminator. The generator is trained to generate new examples of a real image from a dataset. The subsequent images produced, along with a mix of real images from the domain, are then sent to the discriminator, which tries to classify the examples as either real or AI-generated. This task is treated as a zero-sum game – where one model’s gains are the other’s losses – until the discriminator model is fooled around half the time.
Some of the most interesting applications of GANs come in the form of AI art – a prime example being Midjourney. Utilizing a generative adversarial network, Midjourney is capable of creating one-of-a-kind images based on user input. This includes combining traditional painting techniques and algorithmic processes to create unique and unpredictable images. Below is Midjourney’s interpretation of my prompt: Warren Buffet eating at a buffet with Tiger Woods.
2. Transformers
Transformers differ from GANs in both their functionality and architecture. Originally built to handle sequence transduction, Transformers have transformed into a tool that is capable of understanding text, images, and – as I’ll get to later – other forms of data. This is done by imitating cognitive attention and measuring significance of various parts of input data. The below diagram explores what the internal architecture of a transformer looks like:
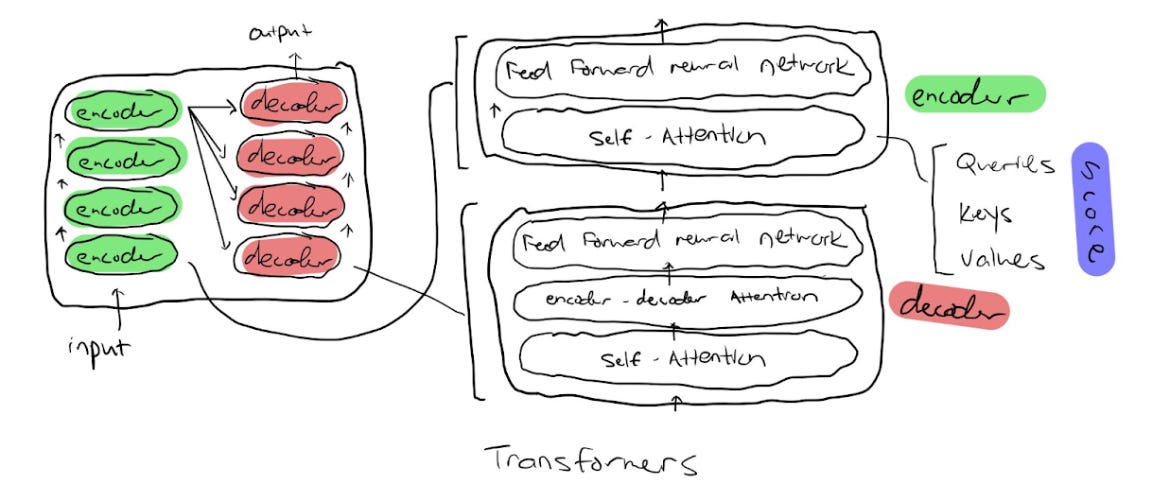
Following the input value into the transformer, we can see that it is first met with a series of encoders, all very similar to one another. Each encoder consists of two layers: self-attention and a feed-forward neural network. The self-attention layer helps the encoder look at other words in the input sentence while encoding the specific input word. The self-attention layer calculates the weighted sum of a particular input value using three vectors: a Query vector, a Key, and a Value vector. These vectors are abstractions for calculating attention in every encoder, baking in its knowledge from previous values in a sentence. The output is then passed through to a decoder that consists of three parts: another self-attention segment, an encoder-decoder attention segment, and another feed-forward network.
Transformers have quickly become the AI architecture of choice for applications involving word recognition that focus on predictive text. Most notable, is OpenAI’s Generative Pre-trained Transformer (GPT) models, like ChatGPT from above. OpenAI’s most recent GPT-3 model was trained with 175 billion parameters, 100 times more than its predecessor, GPT-2. When it comes to language models, size really does matter. GPT-3 has the ability to perform on-the-fly tasks that it was never explicitly trained on, like writing code or unscrambling words in a sentence. ChatGPT was built off of GPT-3, providing an interactive back-and-forth dialogue when answering questions from a user. This anthropomorphic nature of ChatGPT is what has led it to become so popular, allowing users to have full-blown conversations with the AI model.
3. Variational Auto-encoders (VAEs)
A VAE is an autoencoder whose training is regularized to avoid overfitting and optimize latent space. To understand what this means, it’s important to understand dimensionality reduction, or the process of reducing the number of descriptive features in machine learning. When an encoder compresses data from the initial space into the encoded space (latent space), information can be lost in the process that can’t be recovered when decoding. Obviously, the goal is to reduce the amount of information lost, so dimensionality reduction typically focuses on finding the best encoder/decoder pair among a given family. To succeed in doing so, VAEs encode as a distribution over the latent space, rather than encoding an input as a single point. While not as popular as transformers, VAEs are used typically for learning latent representations, drawing images, and completing semi-supervised learning projects.
World View
OpenAI has quickly become the face of generative AI with their creations of DALL-E, GPT-3, and ChatGPT. With the development of these models, Microsoft has also contributed large investments into the company. Most recently, the company is in talks to sell existing shares in a tender offer, valuing the company at around $29 billion. Even despite the current tech downturn amid the poor economic environment, the explosion of AI, especially with this valuation of OpenAI, definitely signifies a strong future in this sector. That being said, there are a couple of concerns that I have with generative AI that need to be addressed before large-scale implementation of these products.
There’s the problem of ownership and plagiarism, not in the way of kids using ChatGPT to write essays for them, but in a way more directly related to the AI. Take Midjourney for example. As outlined above, the CNNs needed to train their GANs to be first applied to a set of input data. Midjourney, however, may not have permission to use others’ images in its training causing an interesting predicament. On the other hand, there’s also the question of who owns what the AI creates. In regards to the Warren Buffet x Tiger Woods images created above, do I own them because I wrote the input, or does Midjourney own them because they created the model.
On a different note, AI outputs aren’t always factual, and can actually lead to harm within society. This is what is known as AI hallucination, a confidence response by artificial intelligence that isn’t justified by its training data. While many of these LLMs are predictive text-based models and aren’t actually surfing the web for answers, hallucinations are actually relatively common. Most of the time, this isn’t too big of a drawback. However, when asking AI for a recommended dosage of prescription drugs, the wrong number could have serious side effects. ChatGPT has actually a semi-solution for this problem. With certain responses, ChatGPT will give insight into its own uncertainty, encouraging the user to doubt the validity of its response.
One major future progression of generative AI that I’d love to see is increased integration with search engines. A quick scroll on twitter will find plenty of silicon valley tech bros comparing ChatGPT and Google Search at every level. This, however, is a false dichotomy. Neither have to function independently, and I believe that can actually yield more efficient results if both work together.
The technical architecture of different generative AI models, while unalike, have the same goal: attempts to replicate human thinking. The reality, however, is that this is far from reality. Artificial general intelligence is a far-away idea, but generative AI is the next closest step to achieving that milestone.
I think ChatGPT is just a bunch of guys sitting behind a screen typing our words
This is great stuff